![How We Make Our Carbon Credits Transparent [eng]](/images/blog/purchase-allocations.png)
Recoolit prevents climate change. We keep refrigerants out of the atmosphere and sell carbon credits for the prevented emissions. When you buy carbon credits from Recoolit, you are buying a specific amount of prevented atmospheric warming, denominated in tonnes of CO2-equivalent. Our approach is designed from the ground up for maximum transparency, showing our credit buyers exactly which activities their dollars are supporting on an extremely granular level. In this post, I’ll go over the data structures and algorithms we use to accomplish this.
Background
First, a bit of context. Refrigerants are super-potent greenhouse gasses commonly used in air conditioners and refrigerators. They are commonly vented to the atmosphere by AC technicians at end-of-life or during maintenance. Recoolit provides technicians with the tools, know-how, and incentives to capture these waste gasses instead of releasing them. Then, we destroy the captured gasses in a high-temperature incinerator, permanently preventing their release into the atmosphere.
We cover the costs of this operation by selling carbon credits to individuals and organizations that want to offset their carbon emissions or just put their money towards a good cause. Carbon credits are meant to be a rigorous, transparent way to pay for climate remediation, but the existing system contains serious flaws and most credits are low quality. For instance, Verra, one of the largest registries, has been criticized for allowing carbon credits to be sold for projects that were already underway, and for projects that were not actually preventing warming.
Most carbon credits are generated from big projects covering massive land areas. The projects will go through a third-party verification, but as a credit buyer, what you end up getting is a tiny share of this huge project. If you want to understand what really happened, you need to dig into complex PDFs which assess the project as a whole. It’s hard to understand your specific impact, and to know that your money is making a difference.
Recoolit is dedicated to preventing climate change with full transparency, allowing our credit buyers to see exactly what they’re getting. Here’s how we do it.
The Data
Our software captures data from every step of the process, including:
- The “recovery”, where a technician actually captures the refrigerant. At this step, we collect photos of the equipment that’s being serviced, the reason for the refrigerant recovery, the amount of gas recovered, and the type of gas recovered (though we don’t always know the exact type of gas at this point).
- “Moves”, when the full cylinder of gas passes from one set of hands to another. We keep a detailed chain of custody during transportation and employ GPS tracking on some legs of the journey.
- “Transfers”, when gas is transferred from one cylinder to another. Usually this is done to consolidate gas from a smaller recovery cylinder into a larger storage tank, to free up the smaller cylinder for use in the field. Every time gas is transferred, we keep detailed records on the source and destination cylinders and weights. (Some small amount of gas is always lost during transfers, and the losses are not included in the carbon credits we sell.)
- “Analysis”, to confirm the type and composition of the material we’ve collected and will destroy. Every cylinder of gas we destroy is sampled and analyzed by a commercial laboratory before destruction, and we typically test “upstream” using a more portable identifier as well.
- “Destructions”, when the gas is incinerated.
Note that gas always enters our system through a recovery and leaves it through a destruction (or leakage). However, it can have a very complex intermediate journey, being transferred multiple times between different cylinders and moved around all over Indonesia by third-party logistics providers.
The Status Quo
With most carbon credit purchases, you are buying a small piece of a larger “project”. For instance, we could consider the destruction of 1000 kg of R22 (generating 1960 tonnes of CO2e) a single “project”. Everyone who bought carbon credits from this project would get an identical PDF saying something like “You purchased 0.5% of Recoolit Project ABC-123”. If you wanted more details, you might be able to find an additional, much longer, PDF, where the project would be documented in the technical language of carbon credit registries.

Here’s a real purchase confirmation from a carbon credit seller in the US. We haven’t taken anything out – this is all the data we got.
This approach is universal for carbon credits, but as a buyer, it’s really unsatisfying! More importantly, it’s a big part of why the market is so broken. Lots of carbon credit sellers obfuscate their work as much as possible: they’re scared of scrutiny and competition. That’s not good enough, and so we’ve put a lot of time into doing better even though it might make it easier for our potential competitors.
Building the transfer graph
When you buy a carbon credit from Recoolit, you are buying a specific quantity of a specific gas that was destroyed. We show you all of the data that went into your destruction, so we need to trace the path of the gas from the recovery to the destruction. We call this data structure the “transfer graph”, and it is the core of our transparency system.
The transfer graph is a directed acyclic graph (DAG). In this graph, the edges are transfers from a source to a destination node. Each edge has a weight, which is the amount of gas transferred, as well as a gas type.
Now, our first instinct was that each node in the graph should be a cylinder. After all, transfers in the real world occur between cylinders. However, because we reuse our cylinders, this would have created cycles in the graph. Instead, each node is actually a specific cylinder ID during a specific time interval.
A node is created when gas is first transferred into that cylinder, and “closes” when all of the gas is transferred out and we vacuum out the cylinder. A subsequent transfer into the same cylinder ID would create a new node.
We sometimes do partial transfers – for instance, we want to completely fill a cylinder that we’re sending to destruction, so we top it off from another cylinder, leaving that one partially filled. This means that a node could have multiple outgoing edges, one for each partial transfer out. We use some heuristics to determine if a transfer should “close” a node, mostly having to do with whether or not the node has a meaningful amount of gas remaining.
Finally, each node can have a series of “events” associated with it. Events include things like “the gas was tested”, “the cylinder was transported”, or “the cylinder was weighed”.
An example
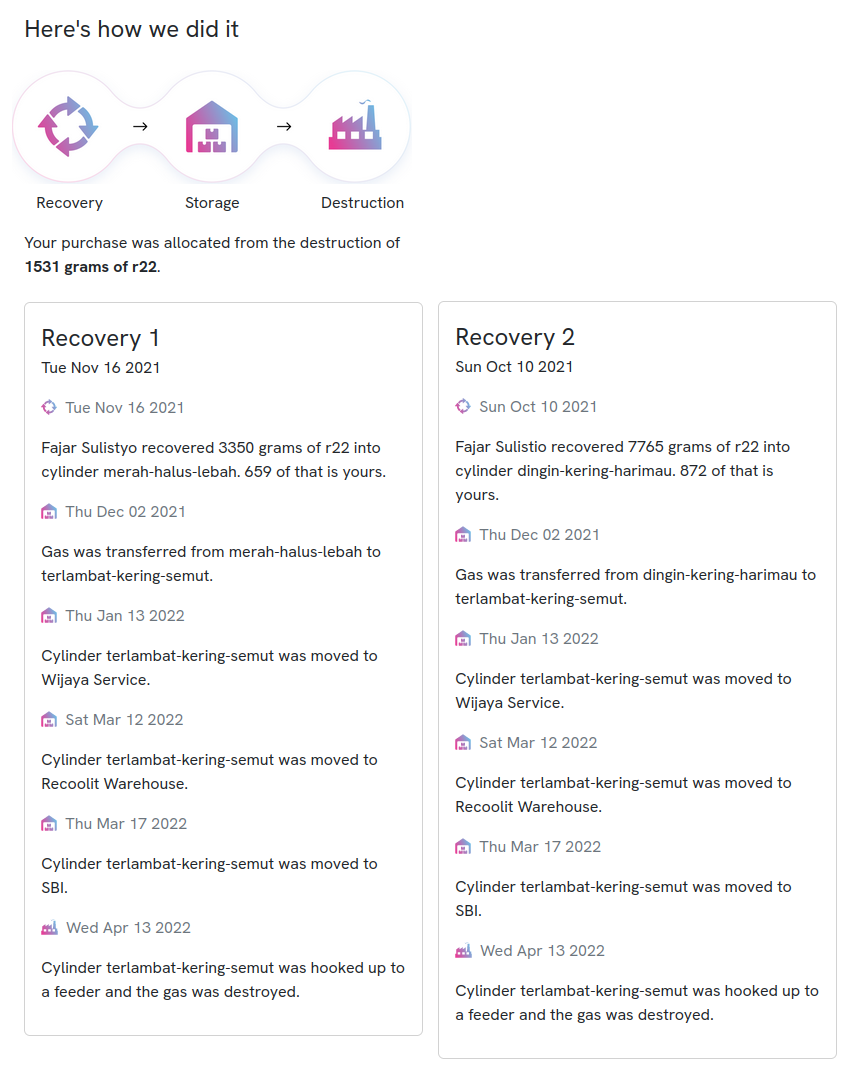
This might be easier with an example, so let’s use some real data from our public registry. I bought some credits from Recoolit, and here is my receipt for that purchase.
This is a view of the same data in our internal system:
This view is generated using the excellent reactflow visualization library. It has a lot of features that allow interactive graph editing, but we mostly just use it for visualization. Unfortunately, reactflow does not do layouts, and our graphs can get pretty large and unwieldy. Instead, we use ELK’s layout engine to do our visualization layouts server-side. We send an already-laid out graph to the UI for display.
We launched our operations before we created this visualization, but it’s been a game-changer. It was very difficult to reason about the structure of our data when it was just a bunch of rows in a table (or spreadsheet, which is where we started!). Getting to actually see the flow of gas through cylinders and events helped us understand what to show our customers, and find ways to improve our internal operations.
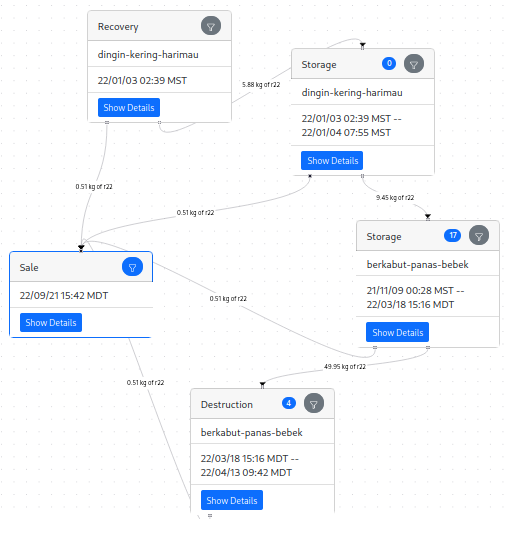
To allocate this purchase, we first look through all of our destructions to find one that has enough gas to cover the purchase. We might need to combine multiple destructions to cover the purchase. In this case, we found that we destroyed about 50kg of R-22 from cylinder berkabut-panas-bebek. R-22 is such a high-GWP refrigerant that only 511 grams of it were needed to cover my purchase of 1 tonne of CO2e.
Next, we do a depth-first search through the graph, starting at the destruction node, and looking for a path that has enough gas to cover the purchase. We see that about 10 kg of R-22 arrived in berkabut-panas-bebek from dingin-kering-harimau, so we allocate 511 grams of that 10kg. Finally, we see that 5.8 kg of R-22 was recovered directly into dingin-kering-harimau, so we allocate 511 grams of that 5.8kg.
This was a fairly easy case, as it only involved a single trajectory through the graph. Here’s an example of a more complicated sale, which involved multiple kinds of gas allocated through multiple destructions:
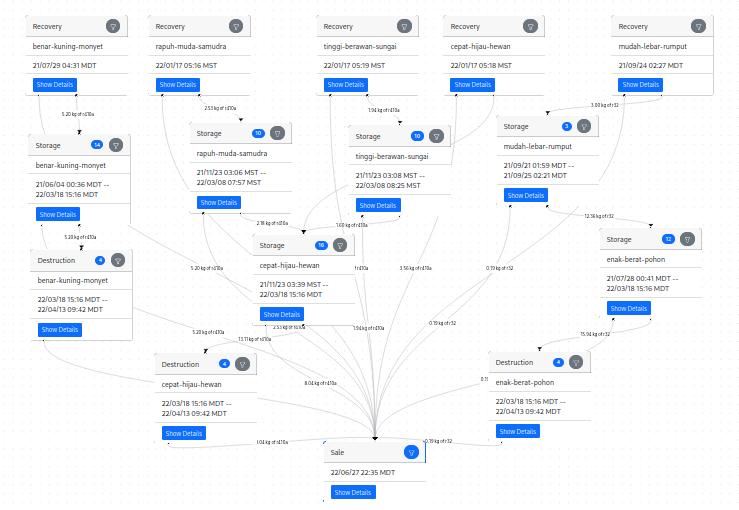
In this case, the purchase of 30 tonnes of CO2e was covered by 3 different destructions. We destroyed 13235 grams of R-410a and 193 grams of R-32 to cover this purchase, and these gasses were recovered by two technicians on 3 different occasions. Three of the five recoveries were on the same day into three different cylinders, indicating a large recovery job that filled up multiple cylinders!
Formatting for display
We’ve already discussed all of the data we collect during operations to enable this kind of transparency. You can now also see how our system allocates your purchase to destructions and recoveries. The final piece is presenting this data in a way that is easy to understand.
In your receipt, we show you a path-decomposed version of the transfer graph. A path is a linked list of edges and nodes, starting at a recovery and ending at a destruction. However, in your purchase subgraph, a single node or edge might be involved in multiple paths. When we do the decomposition, we clone the nodes and edges, so that each path has its own copy. Here’s an example of a non-decomposed graph:
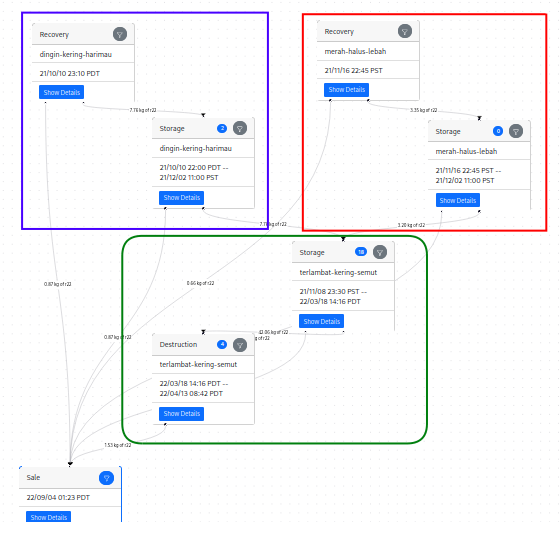
You can see that this includes two recoveries – one in the blue box, and one in the red box. The green box includes a consolidation node and a destruction node that are shared between the two paths. When we display it, it would look more like this:
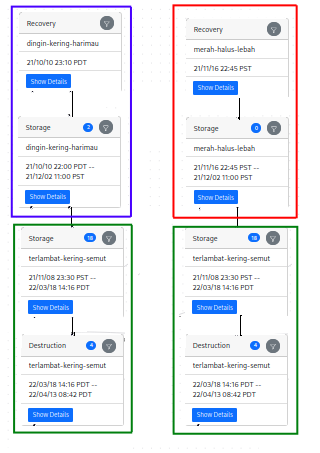
There are two paths in this graph – the one on the left, and the one on the right – and the nodes in green are duplicated between the two paths. Here’s how the same data might look in your purchase receipt:
Doing this is surprisingly non-trivial because it’s not clear, just from the subgraph, how many paths through a particular node there are. To make it easier, we actually keep track of the paths when we construct the graph. Each time we begin trying to allocate gas from a destruction, we generate a path identifier. When we find a path that works, we store the path identifier in the sale edges that track the allocated purchase. This means that a node might actually have multiple edges connecting it to a sale node, each with a different path identifier.
Wrapping up
As you can see, we’ve put a lot of thought into how to make our data as transparent as possible. We have a long way to go, too - we can collect much more data and show more of what we’ve collected, plus integrate this with our third-party verifications. If you’re curious about any other aspect of our approach, feel free to reach out!
Our goal is to create the highest-quality carbon credits, with the greatest possible assurance to buyers that their purchase is actually making a difference. If you like what we’re doing here, and want to support us, we urge you again to buy some carbon credits!
(post by Igor Serebryany)